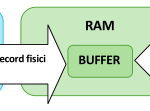
Per consentire ad un’applicazione di avere accesso ai dati memorizzati in un file di archivio, abbiamo visto (link all’articolo) che, per un problema di minimizzazione dei tempi di accesso, è stato necessario implementare il meccanismo del buffer di memoria e dei record fisici e logici. Tale meccanismo viene gestito a LIVELLO DI SISTEMA OPERATIVO e in particolare è affidato ad un suo modulo detto File System, che si occupa di tutta la gestione fisica dei file sulle memorie secondarie, compresa quella che riguarda gli accessi di I/O da parte delle applicazioni. Quando un’applicazione ha bisogno di eseguire un’operazione di LETTURA o SCRITTURA sui dati memorizzati in un file, essa può richiedere di usufruire dei servizi offerti dal File System richiamando apposite funzioni di libreria o utilizzando particolari classi che lavorano sugli stream di input/output nel caso dei linguaggi OOP, che i linguaggi di programmazione mettono a disposizione del programmatore. Esse s’interfacciano con il File System richiamando alcune sue routine specifiche, che sono dette system call (chiamate di sistema) e che in generale costituiscono il meccanismo usato dai processi a livello applicativo per richiedere un servizio al Sistema Operativo.
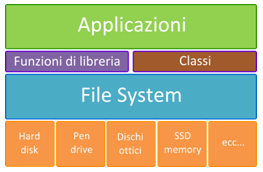
Questo soluzione oltre ad una maggiore efficienza nei tempi di accesso, porta con se molti altri vantaggi. Per esempio, come è stato già accennato sopra, a LIVELLO APPLICATIVO (ossia dalla prospettiva dell’applicazione e del programmatore/utente) i file vengono visti come un’entità astratta unica, univocamente individuata da un nome logico costituito dal suo nome, completo di estensione e path (il percorso che individua la posizione logica del file all’interno dell’albero delle directory o cartelle), quando in realtà quel file può essere composto da molti record fisici, memorizzati in maniera discontinua in blocchi fisici separati della memoria secondaria. Questa situazione è tipica per tutte le memorie secondarie, fatta eccezione per i nastri magnetici. E ancora, grazie a come ciascun file viene gestito e, in particolare, per il fatto che sulle memorie secondarie il File System può organizzarlo in un numero a piacere di blocchi fisicamente separati, il file è una struttura dati dinamica nel senso che la sua dimensione non deve essere fissata a priori quando esso viene creato e può variare senza alcun problema nel corso del tempo. Inoltre, almeno teoricamente, si può dire che non ci sia un limite massimo per la dimensione che un file può raggiungere, l’unico limite è quello dettato dalla capacità in byte della memoria secondaria su cui risiede e dalla capacità massima di gestione da parte del Sistema Operativo.
In definitiva, grazie a questo meccanismo il File System nasconde al LIVELLO APPLICATIVO la reale suddivisione fisica dei file e un’applicazione può avere accesso ai record logici memorizzati in un file e operare su di essi in modo molto semplice, astraendosi completamente da tutte le operazioni fisiche che vengono coinvolte e che sono invece affidate al Sistema Operativo, e operando solo ad un LIVELLO LOGICO. Ossia, a livello applicativo si consegue l’importantissimo vantaggio che un file può essere utilizzato come una struttura dati astratta composta da una sequenza contigua di record logici, all’interno della quale le applicazioni possono richiedere di effettuare operazioni di lettura e scrittura a livello di singolo record o addirittura, prevedendo un’opportuna organizzazione logica del file, a livello di singolo campo.