In un precedente articolo (link articolo) abbiamo esaminato il caso più semplice di organizzazione degli archivi ad indice, ossia quella a singolo indice con indicizzazione completa. Abbiamo visto che essa permette di ottenere un accesso associativo ai record di un archivio garantendo buone prestazioni. Queste, però, tendono a degradarsi quando la mole di dati diventa consistente. Infatti, al crescere dei numero di record memorizzati nell’archivio principale, cresce anche la dimensione del file dell’indice, per cui l’indicizzazione completa delle chiavi primarie ha il difetto di determinare un calo delle prestazioni dovuto al crescere del numero di accessi di I/O alla memoria di massa necessari sia in fase di ricerca, sia in fase di inserimento per mantenere ordinato il file dell’indice. In questi casi una prima soluzione può essere una variante dell’organizzazione sequenziale a singolo indice, detta a singolo indice con strutture ordinate.
L’organizzazione a singolo indice con strutture ordinate
L’organizzazione a singolo indice con strutture ordiante prevede che l’archivio principale venga organizzato in una struttura a pagine (sottoarchivi), secondo lo schema dell’esempio della figura seguente.
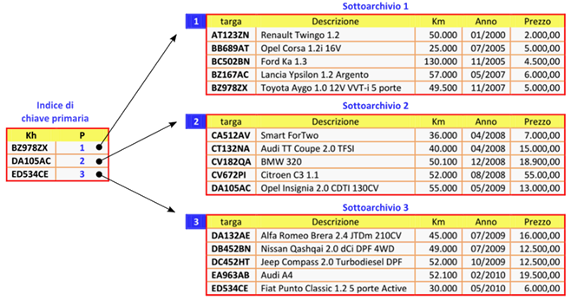
Nel file indice, inoltre, che è ordinato rispetto al campo delle chiavi primarie, questa volta non è presenta un’indicizzazione completa delle chiavi, ossia in esso le chiavi primarie non sono presenti tutte e, in particolare, esse sono costituite solo dalle chiave più alte, ossia le chiavi dei record che occupano l’ultima posizione in ciascun sottoarchivio. Si noti, infatti, che anche i sottoarchivi globalmente sono ordinati rispetto alla chiave primaria (strutture ordinate).
Ciascun record del file indice, infine, individua uno dei sottoarchivi utilizzando opportunamente il suo campo puntatore. In definitiva, i record del file indice hanno un tracciato record del tipo:
(Kh, P)
dove Kh indica la chiave primaria più alta del sottoarchivio a cui punta il puntatore P. Con questo tipo di organizzazione l’indice di chiave primaria viene utilizzato solo per individuare il sottoarchivio all’interno del quale il record cercato deve essere ricercato (si fa notare che si potrà utilizzare un qualunque algoritmo di ricerca, sequenziale o binaria, visto che il sottoarchivio è ordinato, ovviamente per migliorare le prestazioni si preferirà la ricerca binaria). In particolare, la procedura di ricerca di un record con chiave priamaria K prevede i seguenti passi:
- ricercare nel file indice il primo record con un valore di Kh maggiore o uguale di K;
- accedere al sottoarchivio puntato dal campo P del record trovato al punto precedente;
- ricercare il record con chiave K nel sottoarchivo del punto precedente.
Si fa notare, infine, che nonostante l’archivio principale risulti suddiviso in sottoarchivi, comunque continua ad essere possibile eseguire una scansione sequenziale dell’intero archivio principale seguendo il cammino fissato dal file indice.
Organizzazione ad indici su più livelli
Con la soluzione precedente man mano che il numero di record memorizzati in ciascun dei sottoarchivi cresce, la ricerca in essi si appesantisce e di conseguenza le prestazioni degradano. Per migliorarle si può tentare di aumentare il numero di sottoarchivi, in modo da diminuire il numero di record in cui, abbiamo visto, ogni volta bisognerà eseguire la ricerca. Si fa notare però che, all’aumentare del numero dei sottoarchivi, aumenta anche il numero delle chiavi del file indice, pertanto, se il numero di record cresce in maniera rilevante, anche questa organizzazione dell’archivio viene messa in crisi. Per migliorare le prestazioni che in generale tendono a peggiorare sia al crescere del numero dei record memorizzati nei sottoarchivi, sia al crescere del numero dei sottoarchivi utilizzati, si può pensare di estendere la soluzione dell’indicizzazione a strutture ordinate all’indice stesso, ossia l’indice stesso può essere organizzato in pagine (sottoarchivi). La figura seguente mostra il caso più semplice di questo tipo di organizzazione ad indice su 2 livelli.
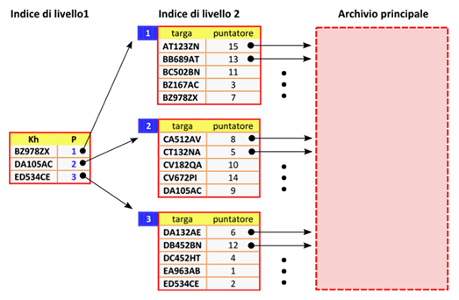
Nell’esempio della figura l’archivio principale è realizzato come un semplice archivio ad organizzazione sequenziale, ossia a struttura non ordinata con l’inserimento dei nuovi record in coda. In questo caso, quindi, il file indice di livello 1 serve per individuare il sottoarchivio di livello 2 in cui ricercare la chiave del record cercato e nel file indice di livello 2, invece, il campo puntatore contiene la posizione occupata dal record con il valore di chiave corrispondente, all’interno dell’archivio principale. Il pregio di questa soluzione è che il fattore di blocco dei vari sottoarchivi del file indice di livello 2, sicuramente è aumentato rispetto a quello dei sottoarchivi dell’archivio principale della soluzione precedente e ciò sappiamo (link articolo) è un vantaggio in quanto si traduce in una diminuzione del numero medio di accessi alla memoria di massa necessari per compiere sia le operazioni di ricerca sia quelle di ordinamento.
Più in generale, l’organizzazione precedente può essere iterata strutturando la gerarchia dell’indice su un numero maggiore di livelli e, ad ulteriore garanzia delle prestazioni, anche l’archivio principale può essere realizzato a pagine di strutture ordinate. La figura seguente mostra un esempio di organizzazione ad indice su più livelli a strutture ordinate.
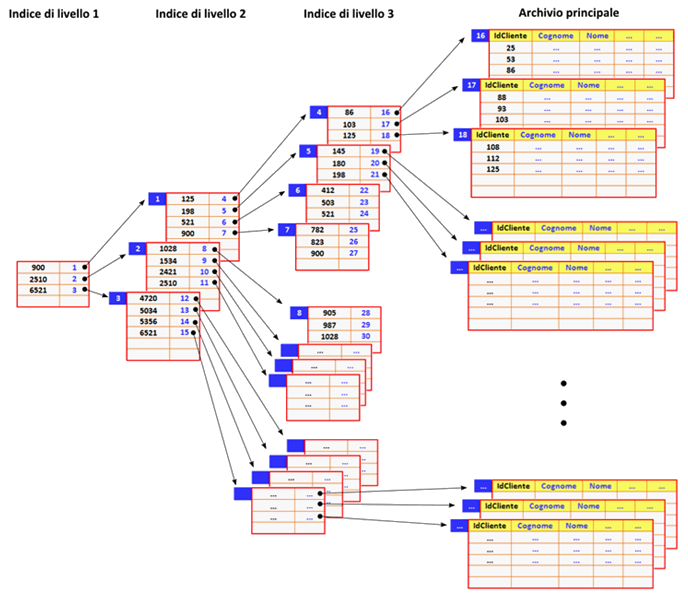 Con un’organizzazione ad indice su più livelli a strutture ordinate, in generale, partendo dal primo sottoindice, ciascun sottoindice di livello k viene utilizzato per individuare quale sottoindice di livello k+1 debba essere esaminato per muoversi nella gerarchia degli indici, così da poter raggiungere il sottoarchivio all’interno del quale ricercare il record cercato. In questo modo si riduce drasticamente il numero dei record fra i quali effettuare le ricerche e di conseguenza anche il numero di accessi alle memorie di massa necessari, con il risultato di un miglioramento delle prestazioni dell’archivio anche se il prezzo da pagare, ovviamente, sarà una maggiore complessità di gestione dell’archivio da parte del programmatore/programma.
Con un’organizzazione ad indice su più livelli a strutture ordinate, in generale, partendo dal primo sottoindice, ciascun sottoindice di livello k viene utilizzato per individuare quale sottoindice di livello k+1 debba essere esaminato per muoversi nella gerarchia degli indici, così da poter raggiungere il sottoarchivio all’interno del quale ricercare il record cercato. In questo modo si riduce drasticamente il numero dei record fra i quali effettuare le ricerche e di conseguenza anche il numero di accessi alle memorie di massa necessari, con il risultato di un miglioramento delle prestazioni dell’archivio anche se il prezzo da pagare, ovviamente, sarà una maggiore complessità di gestione dell’archivio da parte del programmatore/programma.