I file possono essere classificati in due categorie fondamentali: i file di testo e i file binari. Questa classificazione si basa sul concetto di formato di un file, ossia sulla convenzione di codifica che viene utilizzata in fase di SCRITTURA del file, in base alla quale è possibile dare ai byte in esso memorizzati un significato corretto in fase di LETTURA, attraverso un processo inverso di decodifica.
I file di testo
Un file di testo è costituito da una sequenza di byte che memorizza una sequenza di caratteri. Per rappresentare i caratteri (alfanumerici e di punteggiatura) i file di testo possono utilizzare vari sistemi di codifica, quali i codici ASCII e Unicode.
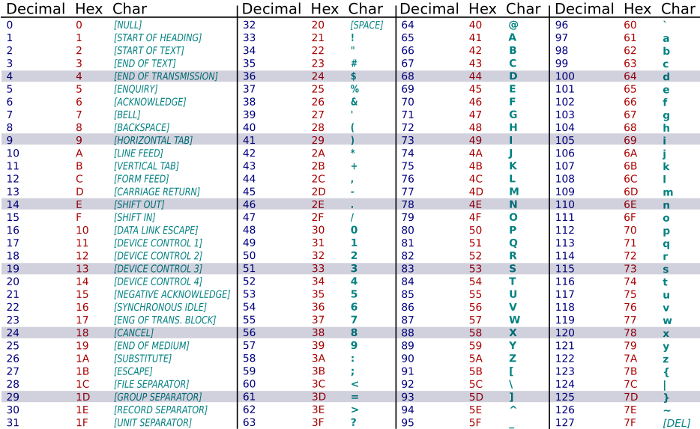
- Il codice ASCII assegna ad ogni carattere un fissato codice numerico (un numero) rappresentato su un certo numero di bit. Questo sistema di codifica originariamente era basato su 7 bit quando nel 1963 (detto US-ASCII) è stato approvato dall’associazione americana degli standard, l’attuale ANSI (American National Standards Institute). Nel corso degli anni a questa codifica dei caratteri seguirono molte proposte di estensione su 8 bit, allo scopo di raddoppiare il numero di caratteri rappresentabili. Una di queste estensioni è diventata uno standard ed è chiamata extended ASCII. Nel codice ASCII esteso sono stati aggiunti i caratteri delle vocali accentate ed altri simboli di uso meno comune. Questo standard utilizza 1 byte per ciascun carattere e permette di codificare 256 (28) caratteri diversi. La figura seguente mostra la tabella del codice ASCII dei primi 128 caratteri (su i primi 7 bit): in essa il codice numerico ASCII associato a ciascun carattere è stato espresso sia in valore decimale (Decimal) sia in valore esadecimale (Hex).
- Il codice Unicode è definito in diverse versioni, l’UTF-8 (che oggi è la codifica Unicode standard per Internet secondo il W3C), l’UTF-16 e l’UTF-32, che utilizzano rispettivamente 8, 16 e 32 bit. Questi sistemi di codifica, senza perderci nei dettagli, utilizzando particolari regole di codifica ed un numero di bit maggiore, permettono di codificare moltissimi caratteri in più rispetto al codice ASCII e rendono così possibile la codifica degli alfabeti di tutte le lingue del mondo.
Esempi
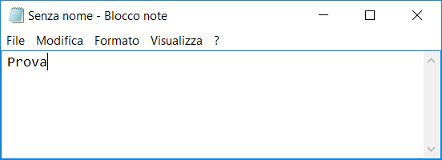
Per ritrovare sperimentalmente il concetto di file di testo, vediamo alcuni semplici esempi. Utilizzando l’editor di testi di Windows, il Blocco note, creiamo il file di testo seguente, contenente solo la parola ‘Prova’ (composta da 5 caratteri).
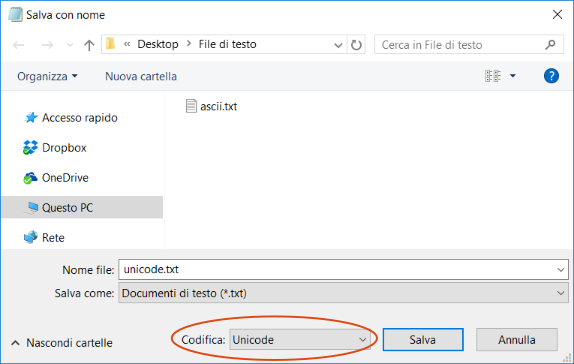
Poi salviamo il file di testo una prima volta nel file di nome ascii.txt in codice ASCII, che è la codifica proposta di default dal Blocco note, e poi una seconda volta nel file di nome unicode.txt scegliendo la codifica UNICODE, così come suggerito nella figura seguente.
I due file di testo creati, come mostrato nella figura di sotto e come potevamo aspettarci, hanno dimensioni diverse.
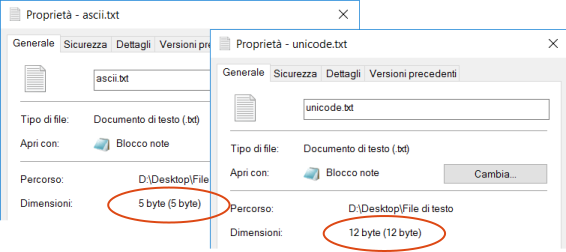
Questo dato può essere confermato anche se apriamo i due file utilizzando un editor esadecimale, in cui è possibile vedere proprio la sequenza dei byte del file rappresentati in valori esadecimali (a ciascun coppia di cifre esadecimali corrisponde un byte).
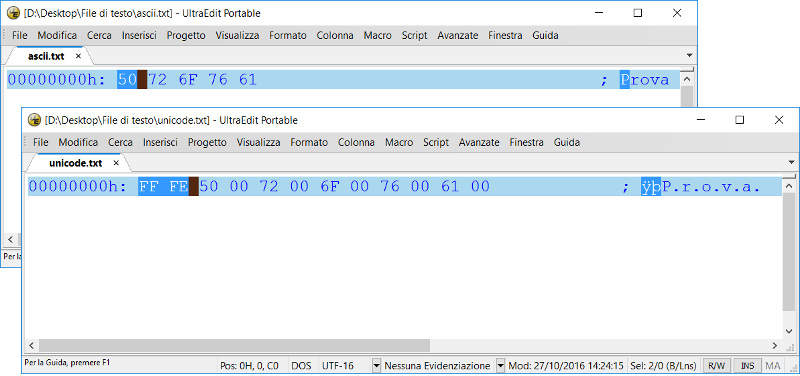
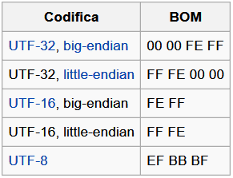
La figura conferma che il file ascii.txt è costituito da una sequenza di 5 byte (ossia utilizza 1 byte per ciascun carattere) che corrispondono proprio ai byte della tabella ASCII mostrata prima, infatti: 50 è il valore esadecimale del carattere ‘P’, 72 quello di ‘r’, 6F quello di ‘o’, 76 quello di ‘v’ e, infine, 61 quello del carattere ‘a’. Il file unicode.txt, invece, è costituito da una sequenza di 12 byte in cui, a partire dal terzo byte, vengono utilizzati 2 byte per ciascun carattere. La codifica Unicode utilizzata, infatti, è l’UTF-16. ln ciascuna di queste coppie di byte, si può notare, il secondo byte è sempre nullo, mentre il primo coincide proprio con quello del file ASCII. Questo si verifica perché nel nostro file di esempio sono stati utilizzati solo caratteri rappresentabili anche nel codice ASCII. I primi 2 byte, invece, sono detti Byte Order Mark (BOM) e servono per indicare il tipo di codifica utilizzata. In un file di testo il BOM permette di identificare subito se il testo è in formato Unicode e, in tal caso, il tipo esatto di codifica. Affinché un programma possa correttamente interpretare il contenuto di un file, infatti, è indispensabile che esso sappia qual è la codifica che è stata utilizzata. E’ proprio grazie al BOM che il Blocco note è in grado di riconoscere la codifica dei file di testo e di mostrarli correttamente, nascondendo all’utente i byte iniziali che compongono il BOM stesso. I byte usati nelle intestazioni dei file di testo nelle varie codifiche sono i seguenti:
Definizione
Un file di testo, in definitiva, è una sequenza di byte di caratteri in genere organizzata in righe separate da una sequenza di byte di nuova riga. Esempi di file di testo sono i file sorgente, i file CSV e TSV (di cui si è parlato in un altro articolo – link articolo) e più in generale i file di archivio sequenziali, i file di log di sistema, ecc.
Una piccola precisazione merita la questione della nuova riga, in quanto le convenzioni per essa adottate dai vari Sistemi Operativi sono diverse. Come mostrato nella tabella seguente, per terminare una riga nei sistemi Windows/MS-DOS si usa la sequenza dei caratteri ASCII carriage return (CR, ritorno carrello con codice ASCII 13) e line feed (LF, nuova linea con codice ASCII 10), mentre nei sistemi UNIX/Linux è sufficiente il carattere ASCII line feed (LF) e in quelli Mac-Os il carattere ASCII carriage return (CR).

La figura seguente mostra un esempio molto semplice di un file di testo ASCII contenente due righe, creato su un sistema Windows e aperto sia nel Blocco note, sia in un editor esadecimale. Nella figura i byte dei caratteri separatori di nuova riga sono evidenziati in giallo.
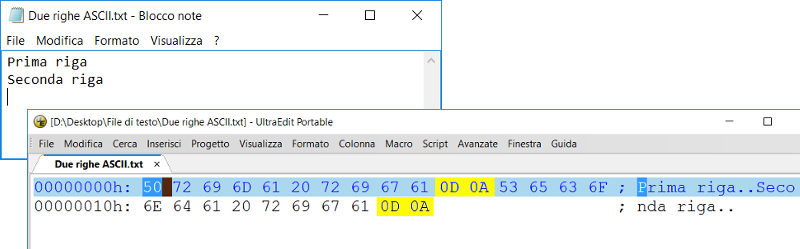
Si sottolinea che queste sono convenzioni dei sistemi operativi e non hanno niente a che fare con le specifiche ASCII. Tali specifiche, infatti, definiscono che il codice 10 (LF) indica uno spostamento verso il basso del cursore mantenendo la stessa colonna, mentre il codice 13 (CR) indica un ritorno del cursore ad inizio riga.
I file binari
Un file binario è un file che può contenere byte di dati di qualsiasi tipo, codificati in codice binario e non solo byte di semplice testo (ASCII o Unicode) come, invece, abbiamo visto accade per un file di testo. Un file binario è una sequenza pura di byte che, quindi, possono rappresentare qualunque tipo di informazione (testi, numeri, immagini, video, ecc.).
Quando un’applicazione legge dei byte da un file binario, essa deve sempre sapere cosa essi rappresentano in modo che possano essere correttamente interpretati (decodificati). Per questa ragione un file binario può essere utilizzato solo dai programmi per i quali esso è stato creato e se si prova ad aprirlo con un editor di testi come il Blocco note, si visualizza una lunga sequenza di caratteri strani senza alcun significato. La figura seguente, per esempio, mostra un file di archivio ad accesso diretto che contiene i record di tre clienti memorizzati in un file binario, aperto con il Blocco note.
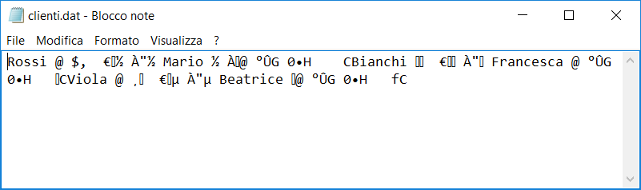
Un file binario viene letto a blocchi di byte che sono interpretati in funzione del tipo di dato che essi rappresentano dall’applicazione per la quale il file viene creato. Esempi di file binari sono il file di un’immagine, un file audio o video, i file nei formati specifici di un’applicazione quali i documenti di Word o di Excel (essi oltre a contenere i byte di carattere del testo, contengono anche i byte delle formattazioni), i file di archivio (diversi da quelli sequenziali, cioè realizzati appunto con dei file binari e non con dei semplici file di testo, come quello della figura di sopra), i file compressi, i file oggetto ed eseguibili, ecc..