In questo post non si ha la pretesa di parlare diffusamente di archivi tradizionali e di database, questo anche per ovvi motivi di spazio visto la vasta portata dell’argomento. Si vuole, invece, solo porre l’accento su alcune caratteristiche fondamentali che li differenziano, per poter evidenziare quali sono le implicazioni più importanti del loro utilizzo nei sistemi informativi.

Gli archivi tradizionali e i database (in italiano base di dati) sono entrambi dei “contenitori” appositamente progettati per la memorizzazione persistente di dati. Questi contenitori in realtà sono dei file, quindi risiedono su una memoria di massa, e contengono collezioni di dati strutturati, ossia dati per i quali è definita un’opportuna organizzazione logica. Ma in che cosa si differenziano e quali sono i vantaggi dell’uno e/o gli svantaggi dell’altro?
Sistemi basati sul File System
(Definizioni)
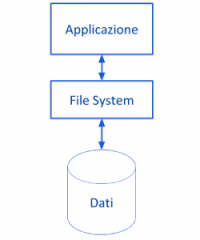
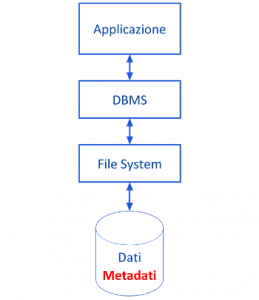
In un sistema informatico per archivio tradizionale s’intende uno o più file di archivio in cui i dati vengono gestiti direttamente dal software dell’applicazione utilizzatrice. Come viene mostrato nella figura seguente, in generale, si ha che per accedere ai dati di un archivio tradizionale, l’applicazione si interfaccia con esso passando solo attraverso il File System. Per questo motivo un sistema informatico che utilizza archivi tradizionali viene anche detto essere un sistema basato sul File System (o file based).
Il File System è quella parte (o modulo) del Sistema Operativo che si occupa della gestione fisica dei file sulle memorie di massa e che fornisce alle applicazioni anche un servizio di accesso ai file. Un’applicazione può richiedere al File System di eseguire operazioni di lettura e di scrittura su un file, utilizzando opportune funzioni di libreria del linguaggio di programmazione che si interfacciano con il File System richiamando alcune sue routine. Attraverso le funzioni di libreria, cioè, le applicazioni sono in grado di effettuare le cosiddette chiamate di sistema (system call) che, in generale, costituiscono il meccanismo con cui i processi applicativi possono richiedere un servizio al Sistema Operativo. Gli effetti di questo meccanismo di accesso ai dati sono rilevanti.
(Conseguenze)
Per cominciare, tutte le operazioni necessarie per la manipolazione dei dati dell’archivio (le cosiddette operazioni logiche: inserimento, modifica/aggiornamento, cancellazione, ordinamento, ricerca ecc.) e, più in generale, tutta la logica procedurale di gestione dell’archivio, è affidata all’applicazione e, quindi, dovrà farsene carico il programmatore. Ciò sicuramente contribuisce a rendere più complesso lo sviluppo di un’applicazione, ponendo anche problemi di efficienza ed efficacia del sistema di gestione dell’archivio.
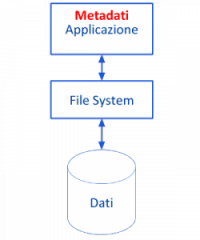
In un sistema basato sul File System, inoltre, il formato con cui le informazioni vengono rappresentate nell’archivio viene fissato con le definizioni delle strutture dati inserite nel codice sorgente dell’applicazione utilizzatrice, con la conseguenza che affinché un archivio sia utilizzabile da un’applicazione è indispensabile che essa disponga della definizione dei dati. L’applicazione, infatti, deve passare la definizione dei dati alle funzioni di libreria, affinché esse possano interfacciarsi correttamente con il File System e in modo che quest’ultimo possa opportunamente operare a livello fisico per collocare e/o recuperare i blocchi di dati sulle memorie di massa. In un sistema basato sul File System la definizione dei dati (i cosiddetti metadati) è separata dall’archivio e si trova nel codice sorgente dell’applicazione. Ciò determina lo stabilirsi di una dipendenza molto stretta tra l’archivio e l’applicazione e, più in generale, la piattaforma hardware/software utilizzata.
Tutto ciò rende difficile e/o limita la possibilità di condivisione di uno stesso archivio fra applicazioni diverse. Si pensi, ad esempio, al caso banale di un’azienda che ad un certo punto introduca nel magazzino l’uso di terminali a radiofrequenza, che sono dei dispositivi sicuramente molto diversi dal resto del sistema informatico da un punto di vista sia hardware, sia software (sistema operativo e applicazioni) o al caso, altrettanto banale, in cui ad un certo punto in un sistema informatico si debba sviluppare una nuova applicazione che richiede di apportare una modifica all’organizzazione logica dei dati.
Un sistema basato sul File System è caratterizzato intrinsecamente da limitate possibilità di condivisione dei dati fra applicazioni diverse e, inoltre, risente di una forte dipendenza logica e fisica dei dati, ossia la modifica della struttura logica e/o fisica dei dati implica dover apportare delle modifiche alle applicazioni utilizzatrici. In genere, pertanto, in un sistema informatico basato sul File System, molte applicazioni che lavorano su stessi contenuti informativi, si ritrovano a lavorare su archivi diversi (separati).
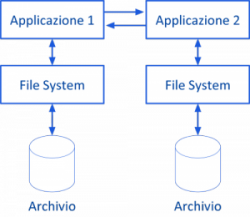
Ciò determina l’insorgenza di ridondanza (o duplicazione dei dati) dovuta alla presenza di copie multiple dello stesso dato, con tutti gli effetti negativi che essa comporta, quali:
- possibile inconsistenza dei dati, ossia il rischio di presenza di copie multiple dello stesso dato, che assumono valori diversi;
- complessità delle operazioni necessarie per aggiornare tutti gli archivi in cui è presente un dato che cambia, con conseguente maggiore complessità dello sviluppo delle applicazioni che devono evitare di introdurre inconsistenza;
- inutile spreco di spazio sui supporti di memorizzazione e di risorse in termini di memoria, CPU e banda delle linee della rete di comunicazione, per la generazione e memorizzazione dei dati duplicati.
Un sistema informatico basato sul File System, dunque, presenta tutta questa serie di inconvenienti, che sono maggiormente sentiti quando deve gestire grandi moli di dati in maniera condivisa. Di solito, infatti, i diversi settori in cui si articola una grande organizzazione e, quindi, le diverse applicazioni che dovranno implementare le diverse funzionalità, hanno in comune molti dati di interesse. Pertanto, una gestione non integrata e condivisa dei dati, implica la necessità di propagare le modifiche fra gli archivi dei diversi settori, determinando tutti gli inconvenienti prima elencati. Ad esempio, se in un’azienda il settore Ordini memorizza i propri dati in un file di archivio non condiviso con gli altri settori aziendali, ogni volta che arriva un ordine, affinché l’ordine possa essere evaso, i dati relativi devono essere trasmessi al settore Spedizioni, e a spedizione eseguita, devono essere ritrasmessi al settore Ordini.
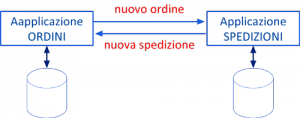
Un altro grosso limite di questo tipo di sistemi, inoltre, è che i meccanismi di condivisione e sicurezza sono limitati ai servizi offerti dal File System che permette di gestirli solo a livello di file. In particolare, essendo il livello di granularità quello del file, per esempio due applicazioni non possono modificare contemporaneamente parti diverse di uno stesso file, così come non è possibile fissare privilegi di accesso diversi per porzioni diverse di uno stesso file.
Sistemi basati su un DBMS
Da quanto detto finora, è facile osservare che la maggior parte degli svantaggi e degli inconvenienti che possono derivare dalla gestione tradizionale degli archivi, possono essere superati solo con una gestione integrata degli archivi, ossia:
- raccogliendo tutti i dati in un unico grande contenitore, detto database o base di dati;
- progettando il database in modo che i dati possano essere condivisi in maniera semplice da applicazioni diverse e su piattaforme diverse.
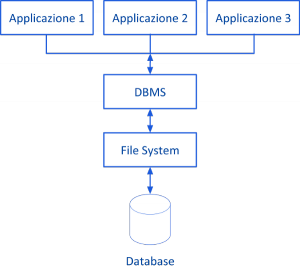
Tutto ciò è stato reso possibile con l’introduzione dei DBMS. Come viene mostrato nella figura seguente, in generale, si ha che un’applicazione per accedere ai dati memorizzati in un database, s’interfaccia con con esso passando attraverso un DBMS.
Un DBMS (DataBase Management System) è un sistema software specializzato nell’archiviazione e nella gestione efficiente ed efficace di grandi moli di dati organizzati in database (o basi di dati), che fornisce dei meccanismi avanzati per garantire l’affidabilità dei dati (fault tolerance), il controllo degli accessi e il controllo della concorrenza. Più in particolare, un DBMS è costituito da un insieme di moduli software specifici, progettati per consentire la creazione, la manipolazione, l’interrogazione e la sicurezza dei database. Un DBMS, inoltre, gestisce i database svolgendo anche la funzione d’interfaccia tra le applicazioni (o anche direttamente gli utenti) e il database, controllando gli accessi e l’integrità dei dati.
Un database (o base di dati) è una raccolta di dati ben organizzata e strutturata per rispondere a determinate esigenze o scopi e progettata per essere gestita da un DBMS. Un database oltre a contenere i dati veri e propri, incorpora in sé anche i metadati.
I metadati presenti in un database, oltre a comprendere la definizione dei dati, possono comprendere anche le regole di integrità dei dati (vincoli), ossia le regole che i dati devono soddisfare per garantire la loro validità e le operazioni che possono essere eseguite sui dati, che non compromettono la validità dei dati stessi.
Affinché tutto ciò sia possibile, un DBMS mette a disposizione di applicazioni ed utenti un linguaggio di definizione, interrogazione, manipolazione e di controllo del database, che è specifico dei database e, quindi, è indipendente dal tipo di applicazione, dal suo linguaggio di programmazione e dalla piattaforma hardware/software. Questo linguaggio è l’SQL (acronimo di Structured Query Language) e ha la caratteristica di essere un linguaggio di tipo dichiarativo (non è procedurale), per cui le applicazioni e gli utenti possono chiedere al DBMS di operare sui dati di un database ignorando completamente quali sono le procedure da eseguire. Esse vengono interamente gestite dal DBMS.
Contrariamente ad un archivio di un sistema basato su File System, un database viene completamente gestito da un DBMS, a cui gli utenti e le applicazioni possono chiedere di utilizzare i dati in maniera molto semplice, adoperando un linguaggio standard. Tutto ciò concorre a rendere possibile e anche molto semplice la condivisione di uno stesso database fra molte applicazioni e utenti diversi e a raggiungere nel sistema l’indipendenza logica e fisica del database.
Per indipendenza logica s’intende la possibilità di apportare delle modifiche alla definizione dei dati, lo schema logico, come ad esempio nel caso dell’aggiunta di un campo ad una struttura dati, senza che le applicazione ne risentano;
per indipendenza fisica, la possibilità di modificare la struttura fisica del database, lo schema fisico, come ad esempio nel caso di modifiche dell’allocazione fisica dei file sulle memorie di massa, senza che ciò influisca sullo schema logico del database e le applicazioni che utilizzano tali dati.
Si precisa che il concetto di integrazione dei dati in un unico grande contenitore, che è implicito nella definizione di database, va tuttavia considerato solo da un punto di vista logico. Da un punto di vista fisico, infatti, un database potrebbe anche non essere composto da un unico file residente su un computer, ma al contrario potrebbe essere costituito da più file, allocati su più computer diversi e facenti parte di una rete i cui nodi si trovano fisicamente lontani. In questo caso si parla di database distribuiti.
Conclusioni
I vantaggi apportati dai sistemi basati su un DBMS, abbiamo visto, sono molteplici e riguardano diversi aspetti:
- sicurezza (riservatezza e integrità dei dati);
- indipendenza dalla piattaforma hardware/software;
- semplificazione dello sviluppo delle applicazioni.
Tuttavia questo non deve indurre a pensare che per lo sviluppo di un’applicazione l’approccio tradizionale sia da scartare a priori. Si fa osservare, infatti, che l’approccio basato sul File System può risultare più efficiente rispetto all’utilizzo di un DBMS, proprio per la maggiore semplicità del primo tipo di sistema. L’utilizzo degli archivi tradizionali risulta essere ancora una buona scelta in quei casi in cui:
- l’applicazione dovrà gestire una piccola quantità di dati;
- ai dati non dovranno avere accesso altre applicazioni;
- le richieste da soddisfare sono semplici;
- non è previsto il porting dell’applicazione su altre piattaforme.